
The Rise of Synthetic Data for AI Training
Artificial Intelligence (AI) models thrive on data. The more diverse and high-quality data they are trained on, the better their performance. But collecting large datasets comes with significant challenges—privacy concerns, high costs, and inherent biases. To overcome these issues, a groundbreaking solution is gaining traction: synthetic data.
Synthetic data is artificially generated using algorithms and simulations that replicate the statistical properties of real-world data. It enables developers to train and test AI systems safely, efficiently, and at scale.
How Synthetic Data Helps Developers
For developers, synthetic data isn’t just a workaround—it’s a productivity booster.
- Accelerates AI Model Training: No need to wait for months of data collection.
- Enables Edge Case Simulation: Train AI on rare or dangerous real-world scenarios, like car crashes for autonomous vehicles.
- Ensures Data Compliance: Reduces the risk of violating privacy laws such as GDPR and HIPAA.
- Supports Innovation: Developers can test bold ideas without being restricted by limited datasets.
Popular Synthetic Data Tools
- Mostly AI – Specializes in structured tabular synthetic data for industries like banking and insurance.
- Synthesis AI – Creates synthetic video and image datasets for computer vision.
- Datagen – Offers realistic datasets for AR/VR, robotics, and automotive.
- Unity Perception – Uses Unity’s game engine to generate 3D visual training data.
- Gretel.ai – Provides APIs for synthetic data generation, anonymization, and augmentation.
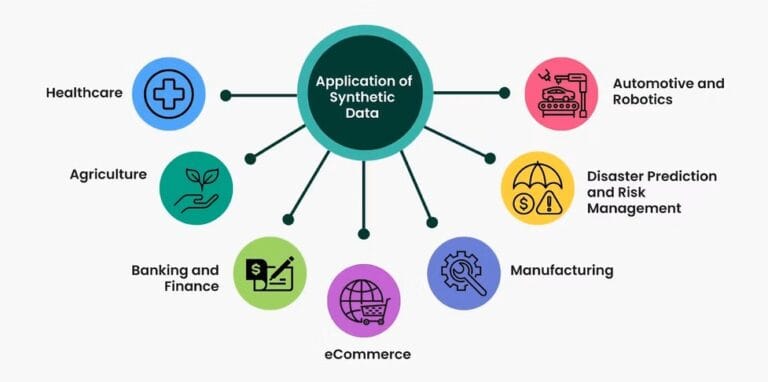
Real-World Applications
- Autonomous Driving: Simulating weather, traffic, and accident scenarios for self-driving cars.
- Healthcare: Generating patient data for research without exposing sensitive medical records.
- Finance: Creating synthetic transaction records to train fraud detection models.
- Cybersecurity: Producing attack simulations to build stronger defense systems.
The Dark Side: Risks of Synthetic Data in AI
While synthetic data offers tremendous potential, it comes with hidden risks that developers and businesses must carefully navigate.
⚠️ False Sense of Security
Synthetic data may give the illusion of privacy, but poorly generated datasets can still leak sensitive patterns from the original data.
⚠️ Bias Amplification
If the algorithms generating synthetic data are biased, the resulting datasets can amplify rather than reduce bias.
⚠️ Overfitting to Unrealistic Scenarios
Models trained solely on synthetic data may struggle in the real world, leading to poor decision-making in critical systems like healthcare or finance.
⚠️ Regulatory and Ethical Uncertainty
Laws around the use of synthetic data are still evolving, creating potential compliance risks.
⚠️ Quality vs. Quantity Trade-off
While it’s easy to generate massive datasets, low-quality synthetic data can harm model performance instead of improving it.
👉 The takeaway: Synthetic data should complement, not fully replace, real-world datasets. A hybrid approach often works best.
🛡️ Protection Against Synthetic Data Risks
To ensure synthetic data remains an asset instead of a liability, organizations should adopt protective strategies:
✅ Hybrid Data Approach – Always combine synthetic data with real-world datasets for more balanced and reliable AI training.
✅ Bias Auditing Tools – Use fairness and bias-detection frameworks to continuously audit both the synthetic data and the models trained on it.
✅ Strict Privacy Safeguards – Ensure algorithms that generate synthetic data cannot leak identifiable information from the source datasets.
✅ Quality Validation Pipelines – Implement validation tests to check realism, diversity, and statistical accuracy of synthetic datasets.
✅ Regulatory Compliance Monitoring – Stay updated with evolving data governance and AI ethics regulations (GDPR, HIPAA, etc.).
✅ Human-in-the-Loop Oversight – Involve domain experts to verify whether synthetic data truly reflects real-world scenarios.
❓ Frequently Asked Questions (FAQ)
It helps protect privacy, overcome data scarcity, reduce labeling costs, and simulate rare or extreme scenarios that may not exist in real datasets.
No. The best approach is a complementary one: synthetic data enhances real datasets but cannot fully replace the richness, complexity, and unpredictability of real-world data.
Synthetic data can introduce bias, give a false sense of security, overfit models to unrealistic scenarios, and create compliance or regulatory challenges.
By using hybrid datasets (synthetic + real), auditing for bias, validating data quality, monitoring for privacy leaks, and including human oversight.
No — synthetic data should be seen as a supplement, not a substitute. While it helps with scale, privacy, and scenario diversity, real-world data is still critical for grounding AI models in reality and ensuring accurate, unbiased performance.



