
🤖 Robotics + AI: How Vision–Language–Action Systems Are Transforming Real-World Robots
“Robots that see. Robots that understand. Robots that act.”
Robotics has changed more in the last 3 years than in the previous three decades — and the biggest breakthrough behind this revolution is the rise of Vision–Language–Action (VLA) systems.
These are AI models that allow robots to see their environment like a human, understand instructions in natural language, and take actions accordingly — all in the physical world.
This is far beyond traditional automation.
We are entering an era where robots learn from video, follow spoken commands, understand context, adapt to changes, and make real-time decisions.
🌟 What Are Vision–Language–Action (VLA) Systems?
Vision–Language–Action (VLA) systems represent one of the biggest leaps in the history of robotics. Instead of programming rigid commands into machines, VLA allows robots to see, understand, and act almost like humans — combining perception, reasoning, and physical execution into one unified intelligence loop. This is the foundational technology powering the next generation of home assistants, industrial robots, autonomous drones, and service bots across the world.
At a high level, VLA systems blend computer vision, natural language intelligence, and motor control policies, enabling robots to operate safely and intelligently in unpredictable, real-world environments.
👁️ 1. Vision (Perception)
The first pillar of a VLA system is vision — the robot’s ability to interpret its surroundings through sensors, cameras, LiDAR, depth scanning, and spatial AI.
Modern VLA robots can perceive:
- ✔ Objects, shapes, and materials
- ✔ Distance and spatial depth
- ✔ Human gestures and body movement
- ✔ Environmental hazards (water spills, fire risk, sharp tools)
- ✔ Dynamic changes like someone moving furniture or dropping objects
These abilities are powered by advanced computer vision models, multimodal AI frameworks, and transformer-based architectures such as Google RT-2, RT-X, GPT-4o, Gemini 2.0, and NVIDIA’s VLA stack. They allow robots to process visual information the same way large language models process text — with context, reasoning, and adaptability.
Vision is no longer just “seeing”; it’s understanding the world in 3D, predicting outcomes, and navigating uncertainty.
🧠 2. Language (Understanding + Reasoning)
The second pillar, language, allows robots to comprehend natural human instructions — not through hard-coded commands, but through true linguistic reasoning.
Robots can understand instructions like:
- “Pick up the red bottle near the microwave.”
- “Organize the table, but leave the laptop untouched.”
- “Move this box to the left room, and avoid stepping on cables.”
Language models help robots interpret:
- ✔ The intent behind the command
- ✔ Context and relationships between objects (“next to,” “behind,” “near the sink”)
- ✔ Safety constraints (“be gentle,” “avoid the edge”)
- ✔ Multi-step instructions (“first clean, then arrange”)
- ✔ Ambiguity and uncertainty (“the blue one” when multiple exist)
This transforms robots from rigid tools into adaptive collaborators capable of reasoning, planning, and responding to complex situations — even when humans give vague or incomplete instructions.
⚙️ 3. Action (Motor Skills + Execution)
The final pillar is action — where the robot turns perception and reasoning into physical movements.
Modern robots powered by VLA can execute:
- ✔ Precise arm and gripper movements
- ✔ Room navigation with obstacle avoidance
- ✔ Object manipulation like folding clothes, wiping surfaces, or opening doors
- ✔ Multi-step tasks requiring planning and sequence tracking
- ✔ Real-time adjustments when conditions change
This involves deep reinforcement learning, motion planning algorithms, and control policies trained on massive datasets of robotic demonstrations.
The “Action” component closes the intelligence loop by enabling robots to act:
- Safely (adapting around humans and pets)
- Smoothly (natural movement, no jerks)
- Intelligently (problem-solving on the fly)
- Autonomously (minimal human correction)
Together, these three components — Vision, Language, and Action — turn robots into real-world agents capable of performing tasks with human-like understanding but machine-level precision.
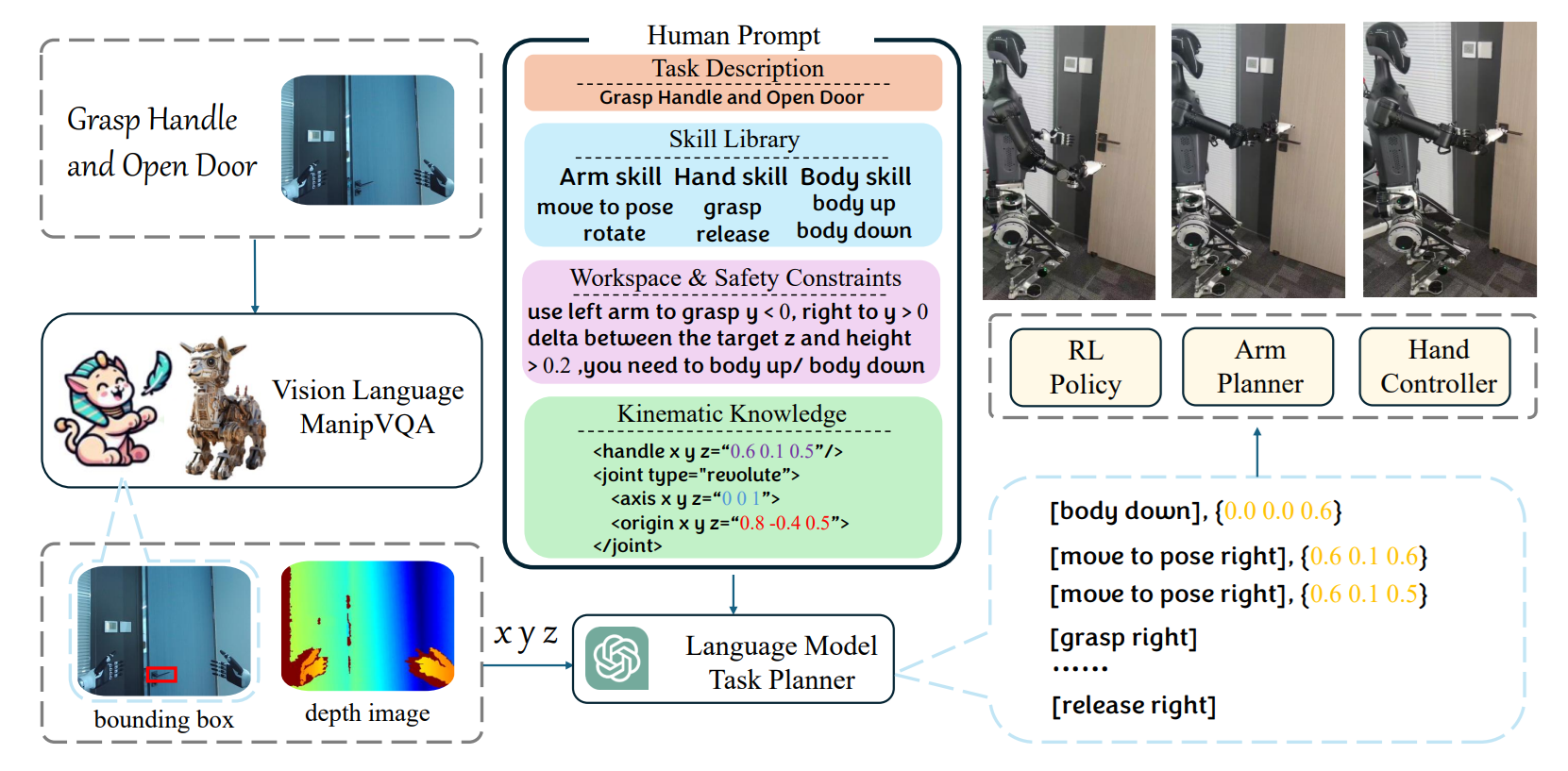
🚀 Why VLA Systems Are a Breakthrough for Robotics
For decades, robotics was limited by rigid programming. Traditional robots could perform only a narrow set of actions — repeating the same movement thousands of times in controlled environments like factories or warehouses. They required perfect conditions, exact placements of objects, and highly structured surroundings to perform even basic tasks. As a result, robots were fast and efficient, but not intelligent.
Vision–Language–Action (VLA) systems change everything.
They represent a monumental shift from pre-programmed automation to general-purpose intelligence, allowing robots to operate in the real world — where things move, change, break, or do not behave as expected.
Here’s why VLA robotics is considered one of the biggest breakthroughs in AI history:
🌍 1. They Learn From Real-World Demonstrations
Instead of writing thousands of lines of robotics code, VLA systems learn by observing:
- YouTube videos
- Workplace surveillance footage
- Synthetic training simulations
- Human demonstrations
- Multimodal AI-generated instruction sets
This enables robots to acquire skills without manual programming, similar to how humans learn by watching others.
🏠 2. They Understand Messy, Unpredictable Environments
Homes, hospitals, and offices are chaotic:
- Objects are misplaced
- Lighting changes
- People walk in unpredictable ways
- Obstacles appear without warning
- Surfaces vary in shape and texture
Traditional robots fail here — but VLA robots excel because they perceive, reason, and adapt like intelligent agents.
🔄 3. They Adapt When Conditions Change
If you move an object, block a path, swap tools, or change the environment, a VLA robot doesn’t panic.
It recalculates:
- New paths
- New grasps
- New strategies
- New sequences of steps
This makes them useful for real-life tasks such as cleaning, caregiving, logistics, and home assistance.
🗣️ 4. They Follow High-Level Natural Language Instructions
For the first time, robots can perform complex tasks based solely on human language.
Examples:
- “Help me pack this room for moving.”
- “Sort these tools and put dangerous ones out of reach.”
- “Prepare a glass of water and bring it to me.”
The robot breaks the instruction into steps, reasons about each step, and executes them safely.
🔁 5. They Self-Improve Through Reinforcement Learning
VLAs are not static systems.
They continuously:
- Learn from trial and error
- Correct mistakes automatically
- Improve efficiency over time
- Fine-tune motion models
- Discover new strategies to handle edge cases
This enables robots to grow their skillset just like a human trainee.
🤖 The Closest Technology to Robots That “Think”
By combining perception, understanding, and action, VLA robots can:
- Make decisions
- Respond to surprises
- Solve tasks in new environments
- Communicate with humans naturally
- Cooperate with other robots or agents
They bridge the gap between rigid machines and adaptive intelligence — bringing us closer than ever to practical household robots, collaborative industrial assistants, and autonomous service bots.
🧠 Retrieval-Augmented Generation
RAG combines the power of large language models (LLMs) with real-time information retrieval, giving AI access to fresh, verified data instead of relying solely on what it already knows.
👉 Learn More🧪 Real-World Examples in 2025–2026
The years 2025 and 2026 mark a turning point in robotics, where Vision–Language–Action (VLA) systems are no longer limited to research labs — they are appearing in real products, real facilities, and real homes. Google DeepMind’s RT-2 and RT-X models are among the most groundbreaking examples. These robots are trained on massive multimodal datasets, including images, videos, actions, and text from all over the internet. As a result, they can perform completely new tasks that they were never explicitly trained for, simply by reasoning through language. If instructed to “pick up the blue sponge under the sink,” an RT-X robot can locate the item, plan the movement, adjust to obstacles, and complete the task — even if it has never seen that room before.
Tesla’s Optimus robot is another powerful demonstration of VLA robotics in action. Instead of relying on rigid programming, Optimus uses vision-driven and language-guided policies to perform tasks such as folding clothes, sorting tools, organizing shelves, and assembling lightweight components in manufacturing environments. The robot learns and refines its skills through enormous amounts of training data and simulation, enabling it to operate in both industrial settings and future household applications. Tesla’s long-term vision is to create an affordable humanoid robot capable of assisting in homes, workplaces, and high-risk environments — and VLA technology is the foundation enabling this transition.
Nvidia’s GR00T initiative represents a different but equally exciting approach. Rather than creating a single robot, Nvidia has built a universal learning agent capable of teaching many different types of robots through imitation, perception, and reasoning — much like how children learn. Robots trained with GR00T can watch demonstrations, understand the goal, and reproduce the behavior across various forms and environments. This dramatically reduces the need for handcrafted robotics code and accelerates the development of general-purpose robots.
In warehouses and logistics centers, VLA-powered robots are becoming the backbone of operations. These robots can navigate aisles, identify products from cluttered bins, optimize paths in real time, and respond to human instructions dynamically. Their ability to understand both visual environments and natural language commands allows them to restock shelves, manage inventory, and even collaborate with human staff more safely and efficiently.
Healthcare environments are also beginning to embrace VLA robotics. Robots equipped with multimodal intelligence can fetch medical equipment, deliver supplies, monitor patient vitals, and assist nurses with routine tasks such as repositioning patients or disinfecting rooms. Their ability to interpret gestures and spoken instructions makes them incredibly useful in fast-paced medical settings where staff are often overwhelmed.
🏢 How Companies Are Using VLA Robotics
Companies across multiple sectors are rapidly adopting VLA robotics because of the flexibility, intelligence, and adaptability they provide. In logistics and fulfillment centers, robots with VLA capabilities can scan shelves, identify misplaced items, pack customer orders, and reorganize inventory layouts automatically — even when human workers change the environment without notice. Smart kitchens and food service operations use similar systems to manage preparation workflows, cook simple meals, clean surfaces, and track ingredient levels without requiring manual oversight. This combination of perception and reasoning allows robots to function like assistants rather than tools.
Inside residential homes, VLA robots are evolving into intelligent helpers capable of folding clothes, cleaning tables, organizing cluttered rooms, and even assisting elderly or disabled individuals with daily activities. Unlike traditional home robots that follow pre-defined patterns, VLA models can adapt to different house layouts, trigger actions based on spoken requests, and make decisions on the fly.
In manufacturing plants, companies leverage VLA systems to handle tasks that are too complex or dynamic for traditional automation. Robots equipped with these models can inspect product quality, assemble multi-component parts with precision, identify hazards such as sparks or leaks, and take corrective actions to prevent accidents. The result is a new generation of robots that not only execute tasks but also understand the environment well enough to collaborate with humans safely.
🛡️ Challenges & Risks of VLA Robotics (and How to Stay Safe)
⚠️ Misinterpretation of Human Commands
One of the biggest challenges with Vision–Language–Action (VLA) robotics is the possibility of command misinterpretation. Natural language is inherently ambiguous, and even the smartest models can misunderstand requests when the wording is vague, emotional, or context-dependent. A simple instruction like “clean the table” may be interpreted differently depending on what objects are on it, how the robot understands “clean,” or whether the robot mistakenly prioritizes the wrong objects. Misinterpretations at the language level can translate into incorrect or unsafe physical actions. To minimize risk, modern robotic systems incorporate confirmation layers where the robot rephrases the task, evaluates potential hazards, and performs intent verification before acting. Increasingly, researchers are adding multi-step reasoning and safety filters so robots cannot execute commands until they match validated safety constraints.
⚠️ Physical Safety Risks Around Humans
Robots interacting in open, real-world environments face a unique set of physical safety challenges. Unlike factory robots that operate inside controlled cages, VLA robots work near families, workers, hospital staff, and vulnerable individuals. Everyday environments are unpredictable — pets move unexpectedly, objects fall, children walk into the robot’s path. Even a small robotic arm can cause serious injury if it moves with uncontrolled force or speed. To address this, robots rely heavily on multimodal sensors (LiDAR, depth cameras, tactile sensors) to detect proximity and motion. Advanced systems enforce dynamic safety zones, restrict force outputs, and apply soft robotics techniques to reduce harm. The emergence of “emergency kill-switch” protocols — both physical buttons and voice-activated fail-safes — ensures that any human can instantly stop the robot in dangerous situations. These features are crucial as robots become common in homes, hospitals, and commercial spaces.
⚠️ Data Privacy & Security Concerns
Because VLA robots constantly process visual, audio, and environmental data, they inevitably capture sensitive information — personal documents, private conversations, faces of children, financial details on screens, and more. This creates significant privacy risks if data is stored improperly or transmitted over insecure networks. To combat this, robotics companies are shifting toward on-device processing, meaning video frames and language inputs stay local instead of being sent to the cloud. Encrypted storage, anonymization layers, and strict access permissions now form the backbone of responsible robotics design. Businesses and homeowners adopting VLA robots must ensure that firmware updates, network configurations, and access logs follow strict cybersecurity standards. Without robust data governance, even the most advanced robotic assistant can become a silent privacy threat.
⚠️ AI Hallucinations & Incorrect Reasoning
A major limitation of VLA systems is the risk of AI hallucinations — moments when the model invents facts, misinterprets visuals, or draws incorrect conclusions. In software applications, hallucinations merely lead to wrong text output. But in robotics, hallucinations can directly translate into harmful physical actions. A robot misclassifying a knife as a harmless object, or incorrectly believing a stove is off, could cause accidents. This is why robotics engineers employ layered safeguards, including rule-based constraints, physics-based action validation, and human-in-the-loop supervision. Robots may be required to simulate actions internally before executing them, effectively asking themselves, “Is this safe?” Some systems compare multiple models or cross-check sensory inputs to avoid acting on hallucinated perceptions. The combination of AI reasoning with traditional robotics safety engineering is essential to prevent real-world harm.
🔥 Final Takeaway
We are entering an era where robots won’t just work — they’ll understand.
Vision–Language–Action systems bring us closer to general-purpose robotics capable of helping people at home, in offices, factories, hospitals, and far beyond.
This is the beginning of intelligent physical automation —
and the students, developers, and businesses who learn it now will lead the next decade.
❓ Frequently Asked Questions (FAQ)
Yes — when designed responsibly. Modern VLA robots include proximity sensors, motion boundaries, emergency stop systems, and rule-based constraints. However, they still require human supervision in unpredictable environments.
Not entirely. They excel at repetitive, physical, or hazardous tasks, but humans are still essential for decision-making, emotional intelligence, and handling ambiguous or high-risk situations. VLA robots work best as assistants, not replacements.
Not always. Many new systems support on-device processing for safety and privacy. However, large updates, cloud models, or remote monitoring may require online access depending on the deployment.
Costs vary widely. Enterprise VLA robots (for logistics or manufacturing) can be expensive, while consumer-level home assistants are becoming increasingly affordable. As technology matures, prices are dropping quickly.
Use local processing when possible, install regular firmware updates, secure your Wi-Fi network, restrict camera access, and enable built-in safety features. Businesses should adopt clear data governance policies and human-in-the-loop workflows.



