
🚀 AutoML 2.0: What Comes After Automated Feature Engineering & Hyperparameter Tuning?
A new era of intelligent, autonomous, production-ready machine learning.
Machine learning has undergone several dramatic transformations over the last decade, but one of the most impactful revolutions was the rise of AutoML 1.0 — platforms such as Google AutoML, H2O.ai, Auto-Sklearn, and DataRobot that automated the repetitive and time-consuming early stages of the ML workflow. For years, data scientists relied on AutoML tools to automatically generate features, tune hyperparameters, select appropriate algorithms, and perform essential preprocessing steps. These tools significantly lowered the barrier to entry, enabling non-ML experts, analysts, and developers to build reasonably accurate models without needing deep mathematical understanding or specialized training. In many ways, AutoML 1.0 democratised machine learning by shifting the focus away from tedious experimentation and toward practical problem-solving.
However, by 2026, the landscape of machine learning has evolved far beyond simple model training. Companies today manage massive, constantly changing datasets; pipelines span real-time streaming sources, multi-modal inputs, and multi-cloud environments; and business decisions increasingly require automation that adapts in minutes, not months. As ML systems move from offline experimentation to fully operational, mission-critical infrastructure, traditional AutoML begins to show its limitations. The true bottleneck is no longer hyperparameter tuning or feature engineering — it’s ensuring that models stay reliable, updated, ethical, and high-performing in an ever-changing environment.
This shift in industry needs raises an essential question: what happens after we automate model creation? If AutoML 1.0 mastered the art of helping us build models, what will help us maintain, evolve, monitor, govern, and optimize them in real-time production environments? As organizations deploy thousands of ML models across departments, edge devices, customer touchpoints, and autonomous systems, the need for smarter, self-correcting AI pipelines has never been greater.
This is why the world is now transitioning into AutoML 2.0 — an entirely new generation of automation designed not just for model building, but for end-to-end lifecycle management. AutoML 2.0 introduces autonomous monitoring, automated retraining, data drift detection, ethical governance, multimodal intelligence, agent-driven optimization, and continuous learning. Rather than focusing on a single stage of ML development, AutoML 2.0 acts as an intelligent co-pilot that keeps the entire pipeline healthy, adaptive, and production-ready. It transforms ML systems from static artifacts into living, evolving ecosystems.
In many ways, AutoML 2.0 marks a profound shift in the AI industry:
From automation of tasks → to automation of intelligence.
From “build a model once” → to “maintain models continuously.”
From manual ML workflows → to AI-driven autonomous ML pipelines.
AutoML 2.0 isn’t just a technical upgrade — it represents a new philosophy for how machine learning should operate in modern businesses. It’s built for a world where AI systems must scale globally, update themselves under changing conditions, follow compliance rules automatically, and remain trustworthy in high-stakes decision-making. It’s the next step toward self-managing AI infrastructure — the foundation required for truly intelligent enterprises.
Welcome to AutoML 2.0 — where machine learning doesn’t just automate the past… it prepares for the future.
🧠AutoML 2.0 = Full-Lifecycle Automation
AutoML 1.0 revolutionized machine learning by making it easier to build accurate models without deep expertise. It automated feature engineering, hyperparameter tuning, and algorithm selection — dramatically speeding up experimentation. But once a model was trained and deployed, AutoML’s job essentially ended. In production environments, this left teams with the ongoing burden of monitoring performance, detecting drift, managing retraining cycles, debugging pipelines, and ensuring compliance. As data volumes grew and business contexts changed faster than ever, this manual workload became unsustainable.
AutoML 2.0 completely redefines the purpose of automation. Instead of stopping at model creation, it automates the entire lifecycle of an ML system — from ingestion to deployment to long-term maintenance. In this new generation, models are treated as living systems that must continuously adapt to shifting data patterns, new user behavior, market changes, regulatory requirements, and updated business objectives. AutoML 2.0 is designed to keep models evolving, improving, and self-correcting without constant human intervention.
The transition from AutoML 1.0 to AutoML 2.0 mirrors the evolution from simple calculators to intelligent assistants. Traditional AutoML solved “how do we build a model quickly?”, but AutoML 2.0 solves “how do we keep thousands of models accurate, compliant, and production-ready every day?” The new wave of automation integrates seamlessly with MLOps, observability platforms, cloud deployment systems, and governance layers to deliver continuous operational intelligence.
AutoML 2.0 takes responsibility for critical tasks that once required large engineering teams:
Data Drift Detection
Modern systems experience constant data drift due to changing user patterns, seasonality, new markets, or unexpected events. AutoML 2.0 continuously analyzes incoming data and compares it with historical patterns to detect even subtle drifts. When drift occurs, the system automatically alerts teams or triggers retraining processes. This ensures the model never becomes outdated or misaligned with the real world.
Continuous Retraining & Model Refreshing
Instead of waiting for a quarterly review or manual intervention, AutoML 2.0 retrains models automatically whenever performance dips or when enough new relevant data is available. This creates a system that adapts in real time — crucial for environments like finance, retail, healthcare, and cybersecurity.
Real-Time Deployment & Rollbacks
AutoML 2.0 can deploy new model versions instantly and roll back automatically if anomalies or performance degradation occur. It behaves like a safety net, ensuring that even risky updates don’t disrupt business operations.
Performance Monitoring & Diagnostics
Every prediction, latency spike, accuracy drop, or anomaly is logged, analyzed, and visualized. AutoML 2.0 generates insights into feature importance shifts, data quality issues, distribution mismatches, and unexpected correlations — helping teams identify root causes early.
Self-Healing Pipelines
If a data source fails, a transformation step crashes, or a model node becomes unstable, AutoML 2.0 can repair or reroute the pipeline automatically. It ensures continuity without manual debugging, making ML infrastructure far more resilient.
Governance, Compliance & AI Ethics
Modern regulations require transparency, fairness, auditability, and controlled access. AutoML 2.0 automatically enforces governance policies, logs decisions for audits, detects bias patterns, and documents model behavior — supporting compliance with laws like GDPR, HIPAA, and AI Act regulations.
Combined, these capabilities transform AutoML from a simple model generator into a full-scale autonomous MLOps system. In fact, the best way to describe AutoML 2.0 is:
AutoML 2.0 = AutoML + MLOps + Observability + Governance in one intelligent layer
This holistic approach ensures that ML systems are no longer static artifacts that degrade over time. Instead, they evolve with the world around them — remaining accurate, reliable, safe, and fully aligned with business needs.
AutoML 2.0 is not just a technical enhancement; it is the foundation for future AI-driven enterprises. In a world where ML systems must operate across thousands of use cases and adapt continuously, AutoML 2.0 becomes the invisible engine that keeps AI trustworthy, efficient, and always production-ready.
🛠️Autonomous Data Understanding (ADU): The Next Frontier
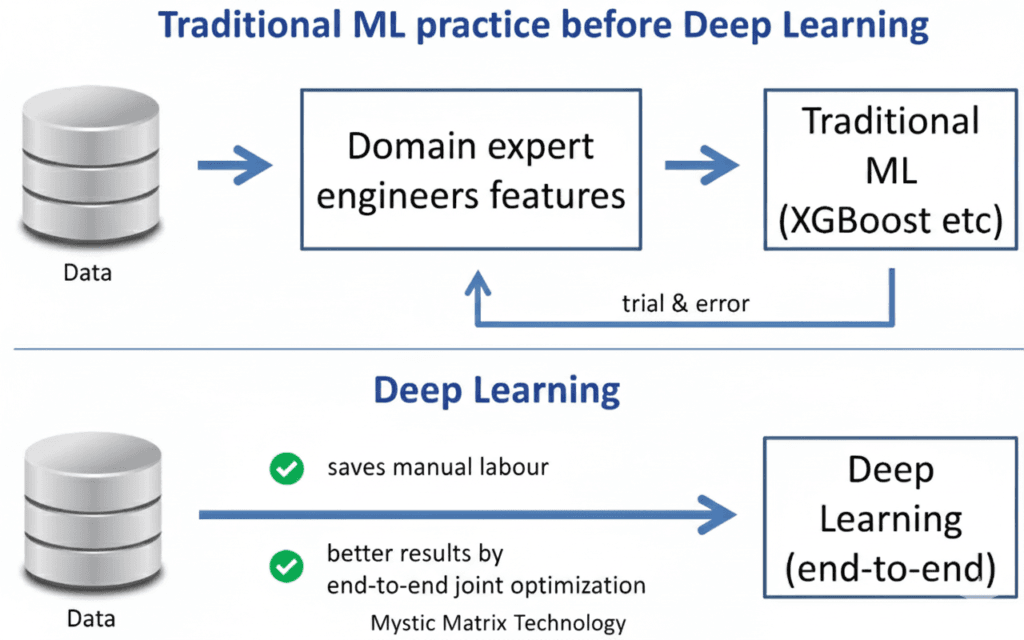
For years, feature engineering was considered the “last frontier” of automation. AutoML 1.0 solved this by automatically generating mathematical transformations, aggregations, and interaction features. But in 2026, the bottleneck has shifted. The core challenge is no longer creating features — it is understanding what the data actually represents. Most enterprise datasets come from different systems, contain inconsistent values, use varied naming conventions, and lack clear documentation. Humans spend 60–80% of ML project time simply figuring out what the data means. AutoML 2.0 introduces Autonomous Data Understanding (ADU) — a leap that allows AI to interpret datasets the way a human analyst would.
ADU systems automatically detect whether a field represents a name, an address, a location, a product ID, or a timestamp — even if the column name is vague or misleading. They infer semantics, units, categories, relationships, and dependencies across multiple tables. ADU also identifies subtle patterns: temporal sequences, hierarchies, graph-like structures, or latent connections between datasets. This enables ML platforms to understand context, not just structure.
A major breakthrough is ADU’s ability to detect data quality issues in real time. Instead of waiting for a pipeline to fail, the system flags anomalies, missing values, outliers, duplicates, or corrupted entries — and fixes them through intelligent imputation or automated cleansing. This transforms data quality from a reactive process into an autonomous layer of defense.
Even more powerful is its ability to generate domain-aware features. Instead of generic engineered fields, AutoML 2.0 creates features tailored to each industry: volatility windows in finance, RFM scores in e-commerce, session embeddings in SaaS products, and normalized metrics in healthcare. In other words, AutoML stops being a mathematical tool… and starts becoming a domain analyst.
⚡Multi-Modal AutoML: Beyond Tabular ML
Traditional AutoML was built around tabular datasets — spreadsheets, relational tables, CSV files. But most real-world data today is multi-modal. Customer interactions include text, voice, and usage patterns. Security systems rely on video feeds, logs, and event streams. Healthcare relies on imaging, structured clinical records, genomics, and sensor data. AutoML 2.0 embraces this reality by providing native support for multi-modal learning, allowing different types of data to be combined into a single model.
AutoML 2.0 frameworks can now ingest images, videos, audio streams, time-series logs, sensor data, user text inputs, chat transcripts, embeddings, and graph structures — then fuse these sources into a unified model pipeline. This unlocks new capabilities where tabular-only ML falls short. For example, retailers can merge CCTV footage with POS transaction logs and customer reviews to detect fraud that no single modality could identify alone. Healthcare professionals can combine MRI scans with textual notes and patient conversations to deliver more accurate diagnoses. In manufacturing, machinery sensor data can be paired with technician notes and maintenance logs to predict failures with far greater accuracy.
Multi-modal AutoML also reduces the need for expert ML engineers, who previously had to manually build complex pipelines for each modality. Now the system automatically performs preprocessing, alignment, embedding generation, fusion strategies, and architecture selection. This not only accelerates innovation but democratizes access to multi-modal AI for startups, small teams, and non-experts.
🧪 Mojo: The Next-Gen Language for AI & ML-Driven Systems
That’s where Mojo, developed by Modular Inc., steps in — a new programming language that could redefine how we build and run AI systems
👉 Learn More🔄Continual Learning & Adaptive Pipelines
Machine learning models degrade over time. User behavior changes, markets shift, competitors influence trends, and data sources evolve. Traditional AutoML did well at training strong models initially, but after deployment, those models slowly became obsolete. AutoML 2.0 introduces true continual learning — enabling ML systems to adapt dynamically and autonomously, without manual retraining cycles.
Instead of passively waiting for engineers to check dashboards, AutoML 2.0 continuously monitors incoming data distributions and model outputs. When it detects drift — such as a change in customer behavior, an anomaly in time-series patterns, or a shift in category frequencies — it triggers an automated workflow. This may include retraining the model, selecting a different architecture, or tuning a new set of hyperparameters. Before full deployment, the updated model is tested in a shadow environment or via canary release, ensuring safety and robustness.
If performance drops, AutoML 2.0 performs instant rollbacks to the previous version — a level of resilience usually found only in enterprise-grade MLOps systems. The pipeline becomes self-healing, self-diagnosing, and self-improving. This concept transforms ML operations into a living organism that maintains itself, much like how Kubernetes manages containerized applications autonomously.
In essence, AutoML 2.0 replaces large portions of DevOps and MLOps engineering work, allowing smaller teams to manage massive AI pipelines with minimal effort. Businesses gain reliability; developers gain efficiency; users gain models that stay accurate for the long term.
🔍AutoML for LLMs: The New Evolution
Large Language Models (LLMs) have introduced entirely new challenges: prompt optimization, fine-tuning strategy selection, context window management, retrieval augmentation, hallucination prevention, and multi-agent orchestration. Traditional AutoML was never designed to handle generative systems — but AutoML 2.0 embraces this domain with a new layer of intelligent automation specifically tailored for LLM ecosystems.
AutoML 2.0 automates prompt engineering, iterating variations of prompts to maximize accuracy, reduce inference costs, and minimize hallucinations. It also automates fine-tuning, selecting ideal datasets, cleaning low-quality samples, filtering bias, and evaluating model performance across specific metrics. This creates a standardized, reproducible fine-tuning pipeline.
AutoML 2.0 also enhances RAG (Retrieval-Augmented Generation) by scoring document relevance, optimizing chunk sizes, improving vector embeddings, reducing noise in retrieval, and tuning context windows. This ensures the model retrieves the right information at the right time — critical for enterprise-grade LLM applications.
Beyond single models, AutoML 2.0 manages AI agent architectures, automatically deciding how many agents to use, how they should communicate, and how to orchestrate multi-step tasks. This is essential for workflows where LLMs act as researchers, analysts, coders, planners, and decision-makers simultaneously.
In short, AutoML 2.0 brings the same level of automation that transformed classical ML — but now to the world of generative AI, agents, and enterprise-scale intelligence systems.
🧪Tools Powering AutoML 2.0 (2026)
AutoML 2.0 is not just a concept — it is being actively shaped by a new generation of enterprise and developer-focused tools. These platforms are transforming ML pipelines into self-managed, autonomous systems. Google Vertex AI, for example, has evolved into a full-scale ML operating system. It automatically performs drift detection, manages continual retraining pipelines, and supports complex multimodal workflows that blend text, images, audio, and tabular data. Vertex is also one of the first platforms to integrate LLM lifecycle automation, making it easier for teams to train, fine-tune, and monitor generative models at production scale.
Microsoft Azure AutoML focuses heavily on compliance, governance, and enterprise-readiness — a crucial requirement for industries like finance, government, and healthcare. It enforces Responsible AI rules, implements automated validation checks, documents every model decision, and ensures deployments meet strict regulatory standards. This elevates AutoML 2.0 from an experimental tool to a trusted foundation for mission-critical systems.
DataRobot continues to dominate the space with one of the most mature full-lifecycle automation systems. It handles ingestion, model development, deployment, governance, and monitoring in a unified platform. Its newest AutoML 2.0 capabilities include automatic segment-level analysis, bias detection, and impact estimation — allowing businesses to understand not only accuracy but also risk exposure and ethical implications of their models.
H2O Driverless AI remains the leader in automatic feature engineering, especially for time-series forecasting and structured data. It uses sophisticated heuristics and genetic algorithms to generate industry-grade features that normally require senior data scientists to design manually. Meanwhile, AWS SageMaker Autopilot is reshaping cloud-native machine learning with one-click model generation, real-time debugging, automated deployment pipelines, and deep native integration with other AWS services. It is becoming the backbone for AI-driven applications in startups and enterprises alike.
What makes 2026 unique is that all these platforms are moving toward a convergent evolution — integrating automatic LLM tuning, agent workflow optimization, multimodal fusion pipelines, and continual learning engines. AutoML 2.0 tools are no longer assistants; they are becoming full AI development environments capable of managing entire ML ecosystems end-to-end.
🚀 Why Students, Developers & Businesses Should Care
AutoML 2.0 is not just a technical upgrade — it is a career catalyst and strategic advantage.
For students, AutoML 2.0 is the fastest gateway into the machine learning world. Instead of spending months learning the details of model tuning, feature engineering, or deployment mechanics, students can focus on understanding data, experimentation, and real-world application design. This accelerates their learning curve and allows them to build production-grade ML systems even without advanced math or engineering background. Students graduating in 2026 and beyond will be expected to know how to work alongside automated ML systems — not necessarily how to write every ML algorithm from scratch.
For developers, AutoML 2.0 is a revolution. It removes the need to become deep ML experts to add AI functionality to applications. Backend engineers can plug AutoML APIs into microservices, mobile developers can deploy ML-powered features without worrying about optimization, and full-stack developers can build intelligent dashboards that retrain themselves automatically. AutoML 2.0 handles tuning, scaling, monitoring, and deployment behind the scenes, freeing developers to focus on user experience and business logic instead of infrastructure overhead.
For businesses, the impact is even more transformative. AutoML 2.0 drastically reduces the cost of building, deploying, and maintaining ML systems. It minimizes the risk of model drift — a common cause of financial loss — by monitoring data behavior in real time and triggering corrective actions automatically. It strengthens governance, reduces reliance on a small team of senior data scientists, and enables companies to scale AI across multiple departments simultaneously. With AutoML 2.0, marketing teams can run prediction models without engineering help, operations teams can forecast demand automatically, and finance teams can detect anomalies with self-learning systems.
In short, AutoML 2.0 turns AI from a niche capability into a company-wide superpower. Students gain future-proof skills, developers gain efficiency, and businesses gain competitive advantage. It democratizes machine learning not just for experimentation — but for sustainable, scalable real-world deployment.
❓ Frequently Asked Questions (FAQ)
AutoML 1.0 automated model training, feature engineering, and hyperparameter tuning.
AutoML 2.0 goes further by automating the entire ML lifecycle — including data drift detection, continuous retraining, deployment, monitoring, governance, and LLM optimization.
Yes. AutoML 2.0 removes the complexity of traditional ML pipelines, allowing students to build production-ready models quickly. It helps them focus on understanding data and real-world applications rather than mastering every algorithm.
Absolutely. AutoML 2.0 accelerates workflows, but human oversight is essential for domain expertise, ethical evaluation, strategic planning, and verifying model outputs. AutoML enhances data scientists — it doesn’t replace them.
No. While enterprises benefit from scale, small teams and startups gain even more value because AutoML 2.0 reduces the need for large ML teams. Tools like SageMaker Autopilot, Vertex AI, and DataRobot offer affordable entry points.
Yes — that’s one of its biggest advancements. AutoML 2.0 supports automated prompt optimization, fine-tuning workflows, RAG evaluation, context window optimization, and multi-agent orchestration, making it ideal for modern generative AI systems.



